北京师范大学古汉语大语言模型“AI太炎 2.0”发布会成功举办
发布时间: 2024-08-28
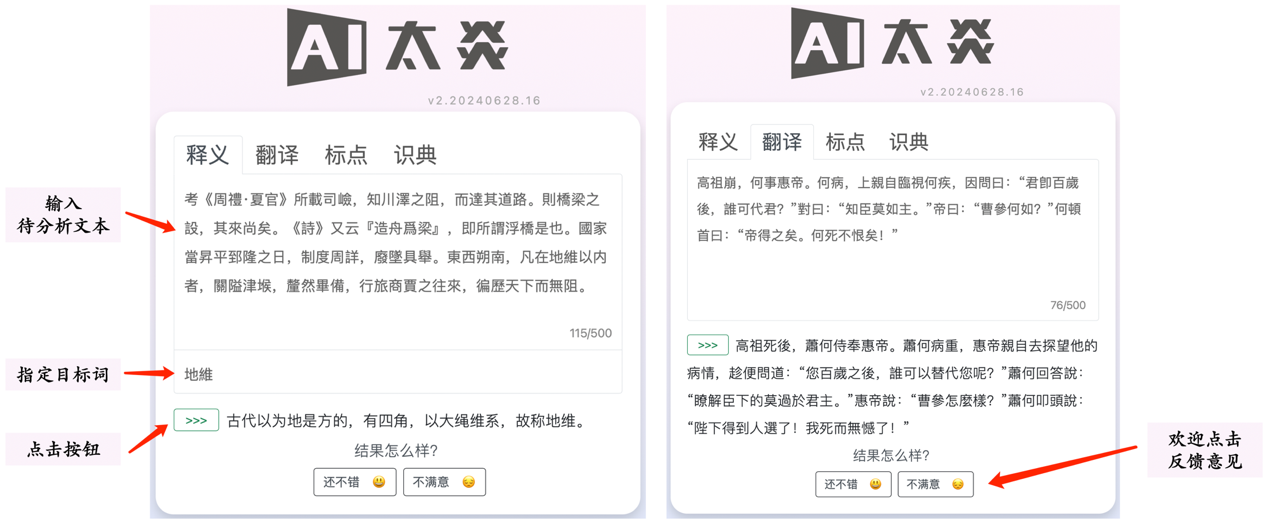
2024年8月27日上午,北京师范大学古汉语大语言模型“AI 太炎 2.0”发布会暨数智时代应用语言学学科建设路径与方法座谈会在京隆重举行。“AI太炎”是我校王立军教授主持的国家语委重大项目“古籍整理智能化关键技术研究”的核心成果,是专门适用于古汉语文本理解的大语言模型。教育部语言文字信息管理司司长刘培俊、北京师范大学常务副校长王守军、北京大学中文系系主任杜晓勤、北京师范大学汉字汉语研究与社会应用实验室学术委员会主任华学诚等领导专家出席会议并致辞,课题负责人、8366cc银河娱乐院长王立军教授对项目进行了介绍,语言学和人工智能领域的三十余位专家学者以及来自俄罗斯、西班牙、爱尔兰、德国、韩国、英国等国的十余位汉学家出席了本次会议。8366cc银河娱乐党委书记周云磊主持发布会,8366cc银河娱乐教授刘利作会议总结。 与会嘉宾会场合影 党的二十大把“实施国家文化数字化战略”作为繁荣发展文化事业和文化产业的重要举措。作为中华优秀传统文化的重要载体,古代典籍的数字化整理与智能化研究,是贯彻落实这一战略部署的关键任务。以北师大王立军教授为主持人的“古籍整理智能化关键技术研究”项目团队,积极利用人工智能前沿技术解决古籍整理与研究中的实际问题,产出了“AI太炎”古汉语大语言模型这一重要成果,回应了党和国家文化事业发展战略的重大需求。 教育部语言文字信息管理司刘培俊司长致辞 在致辞环节,教育部语言文字信息管理司刘培俊司长表示,多年来北京师范大学发挥学科、人才、文化和技术优势,瞄准国际发展前沿,聚焦服务国家战略,深化多方协同创新,在服务国家语言文字规范化标准化、信息化数字化和中国语言文化传播国际化全球化等关键领域不断探索,成就突出,并承建教育部、国家语委语言文字重点科研基地——“中国文字整理与规范研究中心”,为国家语言文字事业发展发挥了重要作用。中心科研团队还承担了教育部、国家语委重大科研项目——“古籍整理智能化关键技术研究”,今天,各位专家很高兴共同见证该重大科研项目成果﹣﹣古汉语大语言模型”AI太炎 2.0”发布。研究表明,大语言模型技术可以大幅提高古籍整理研究效率,可望为普及推广国家通用语言文字、传承弘扬中华优秀语言文化、世界共享中国特色语言文明提供语言智能技术支持。 北京师范大学王守军常务副校长致辞 王守军常务副校长指出,人工智能为人文学科带来了前所未有的机遇与挑战,北京师范大学坚持深入挖掘传统文化内涵,致力于传承民族精神,并积极适应数智时代的发展需求。前沿科技成果“AI太炎”将显著提升古籍整理的效率与精度,对于传承弘扬中华优秀传统文化来说具有重要意义。此外,为探索新文科建设路径,推动学科交叉融合,北师大8366cc银河娱乐近期成立了应用语言学研究所,并联合校内兄弟单位共建“汉语言文学(应用语言学方向)+人工智能”双学士学位培养项目,希望通过上述举措,能够更好地为文化传承与创新发展做出积极贡献。 北京大学中文系主任杜晓勤教授致辞 北京大学中文系系主任杜晓勤提到,北京师范大学在中文信息处理和古籍数字化方面取得了重要突破,为中文学科的传承与发展做出了积极贡献。北师大中文学科历史悠久,名家辈出,凭借其深厚的学术底蕴,在语言信息处理等交叉学科领域不断取得重要成果。近年来,AI古典文献释读能力的进步,极大推动了传统学科在新时代的发展,期待这一创新成果进一步促进中国语言文学学科的繁荣与进步。 北京语言大学教授、汉字汉语研究与社会应用实验室学术委员会主任华学诚致辞 北京语言大学教授、汉字汉语研究与社会应用实验室学术委员会主任华学诚表示,北京师范大学正式发布“AI太炎2.0”古汉语大语言模型,标志着汉语言文字学学科现代化和科学化的转型升级。北师大汉语言文字学有深厚的历史积淀,始终坚守汉语言文字学的传统根基,以高水平的学术成果而闻名,同时积极响应时代要求,推动语言文字学的守正创新,在中国特色现代化道路上展现了人文与学术担当。 项目团队负责人王立军教授介绍项目成果“AI太炎”古汉语大语言模型 项目团队负责人王立军教授在会上介绍了“AI太炎”的研发过程和优势特色。他表示,该模型是针对古汉语信息处理任务“低资源”“富知识”的特点,从头构建的专门适用于古汉语文本理解的大语言模型。通过合理的模型设计、数据处理、基座训练及微调,仅使用1.8B参数量即可取得较好效果。该模型具有较强的古典文献释读能力,支持词义注释、文白翻译、句读标点、用典分析等多种具有挑战性的文言文理解任务,且兼容繁简中文输入。此外,在辅助古籍整理、辞书编纂和语言研究等方面,该模型也表现出了很大的应用潜力。为了致敬近代国学大师章太炎先生,秉承章黄学派弘扬中华优秀传统文化的宗旨,该模型命名为“AI太炎”。 嘉宾代表刘利、周建设、杜晓勤、华学诚与项目负责人王立军、主持人周云磊共同启动系统上线 此前,“AI太炎”1.0版于2023年11月进入内测阶段,海内外学术科研、基础教育、编辑出版等不同行业领域的4000余名用户参与内测,为模型改进提出了宝贵建议。研究团队在此基础上对模型进行了持续迭代优化,并发布了该模型2.0版,以期更好地助力古籍整理、文言文教学和古汉语信息处理研究。目前,用户可通过上述地址访问“AI太炎2.0”公众版,输入待分析的古籍文本后,模型能够根据用户选择进行释读(无需输入提示词),包括解释文本中的疑难字词含义或背后的文化常识,将文言文翻译为现代汉语,对文本进行高精度的句读标点,或识别其所用典故。 “AI太炎2.0”分析示例 “AI太炎”古汉语大语言模型及相关研究成果的发布,标志着我国古籍整理与研究正迈入智能化新阶段。未来,北京师范大学将继续深化产学研用一体化合作,加快培养复合型人才,为传承发展中华优秀传统文化、建设社会主义文化强国贡献更多智慧力量。